Selon wikipedia, « en informatique, la validation des données est le processus qui consiste à s’assurer qu’un programme fonctionne sur des données propres, correctes et utiles. Elle utilise des routines, souvent appelées règles de validation ou routines de contrôle, qui vérifient l’exactitude, la signification et la sécurité des données introduites dans le système. Les règles peuvent être mises en œuvre par le biais des installations automatisées d’un dictionnaire de données ou par l’inclusion d’une logique de validation explicite du programme d’application « .
En d’autres termes, les données sont vérifiées par rapport à un modèle de données. Le modèle de données peut être simple ou élaboré : il appartient au validateur humain de définir dans quelle mesure les données doivent être validées.
Souvent, la validation des données consiste à valider les nombres, les dates et le texte, c’est-à-dire à vérifier les types et les plages. À cette fin, la fonction dédiée d’une feuille de calcul peut faire l’affaire. Cependant, dans un certain nombre d’applications, le modèle de données peut être assez complexe et la vérification difficile à automatiser, ce qui laisse place à des erreurs humaines lors de la validation.
Exemple :
Dans la feuille de calcul suivante, A, B, C et D sont 4 nombres naturels tels que D est la somme de A, B et C.
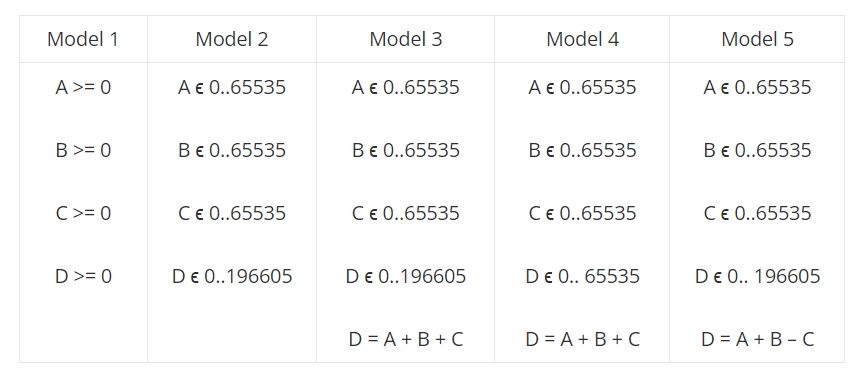
Les modèles 1 à 3 sont corrects : chaque prédicat apparaissant dans la colonne est vrai. Ces modèles répondent à différents niveaux de vérification, le modèle 3 étant le plus complet/le plus contraint. Avec le modèle 1, tout tuple de nombres naturels est acceptable. Avec le modèle 3, seul un ensemble fini de tuples est conforme.
Par ailleurs, il est possible de commettre des erreurs dans un modèle de données, ce qui conduit à des situations où le modèle est partiellement correct. Dans le tableau précédent :
- le modèle 4 n’est pas vérifié si A+B+C >= 65536.
- le modèle 5 n’est vérifié que si C = 0.
Cet exemple est très simple, mais il montre que ce type de vérification est délicat car les données, le modèle ou les deux peuvent être erronés. Il convient donc d’accorder une attention particulière aux questions suivantes :
- comment détecter les données erronées ? Les règles de validation sont la clé. Ces règles, exprimées à l’aide d’un langage mathématique, permettent de spécifier le domaine des données. Les données qui ne correspondent pas à ce domaine sont erronées. Virgule :
- comment s’assurer que les données marquées comme « correctes » sont correctes ? L’homme dans la boucle est une grande source d’erreurs (la V&V est généralement une activité ennuyeuse), en particulier lorsque l’ensemble des données est énorme et que le modèle de données est complexe. La solution consiste à utiliser des outils qui peuvent être rejoués à volonté. La solution idéale serait la redondance, c’est-à-dire deux outils indépendants tirant la même conclusion.
- dans quelle mesure le modèle est-il solide ? Cependant, nous ne sommes pas complètement à l’abri car nous pourrions commettre des erreurs telles que notre modèle défectueux se conforme à nos données défectueuses (errare humanum est, persevare diabolicum). Une autre possibilité est d’avoir un modèle de données « correct la plupart du temps » (mais incorrect dans certains cas qui ne pourraient pas se produire dans un ensemble de données donné mais qui se produiront sûrement plus tard, grâce aux lois de Murphy). On peut envisager de tester les règles de validation pour s’assurer que les données erronées sont détectées, mais cela ne permet pas de prétendre que les données sont définitivement validées, car la plupart du temps, seuls des tests partiels peuvent être réalisés, le domaine de données étant trop vaste.